
前段时间了解到百度云每个月有免费的1000次文字识别(OCR)的接口,马上就去围观领取了。这里记录一下我第一次使用百度智能云的OCR API的过程
1. 光学文字识别
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
PS:上面是我从百度ctrl C V复制来的,改天我另写一篇专门介绍文字识别的博客23333(
2. 为什么要用API
之前我一直有一个疑惑,为什么有开源的库或者模型,仍然有这种API调用的解决方案存在?
这里我可以为你详细解释一下
2.1 API
API(Application Programming Interface,应用程序接口)是一些预先定义的接口(如函数、HTTP接口),或指软件系统不同组成部分衔接的约定。用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。
基于互联网的应用正变得越来越普及,在这个过程中,有更多的站点将自身的资源开放给开发者来调用。对外提供的API 调用使得站点之间的内容关联性更强,同时这些开放的平台也为用户、开发者和中小网站带来了更大的价值。
开放是发展趋势,越来越多的产品走向开放。网站不能靠限制用户离开来留住用户,开放的架构反而更增加了用户的粘性。在Web 2.0的浪潮到来之前,开放的API 甚至源代码主要体现在桌面应用上,越来越多的Web应用面向开发者开放了API。
2.2 API的优势
API开发成本低,对接比较简单,可以快速验证商业模式和用户体验。
说白了,就是API更方便且轻量化,尤其是在一些算力较低的嵌入式设备上。如果动用本地的运算,时间成本会非常庞大;而相反,API能够利用互联网上的高算力设备快速运算,优化用户体验。
3. 从点开百度云官网开始
我直接只接触过腾讯云和阿里云平台对于百度智能云的了解仅限于网盘,不太了解百度云的流程。
点开百度智能云首页 点击上方[产品],找到[人工智能],在该板块内找到[OCR文字识别]-[通用场景文字识别]
注册完成后会有每月500次的体验,实名认证后会有1000次的体验。
3.1 创建应用
在控制台找到文字识别,在“应用”处点击“创建应用”,如下图所示
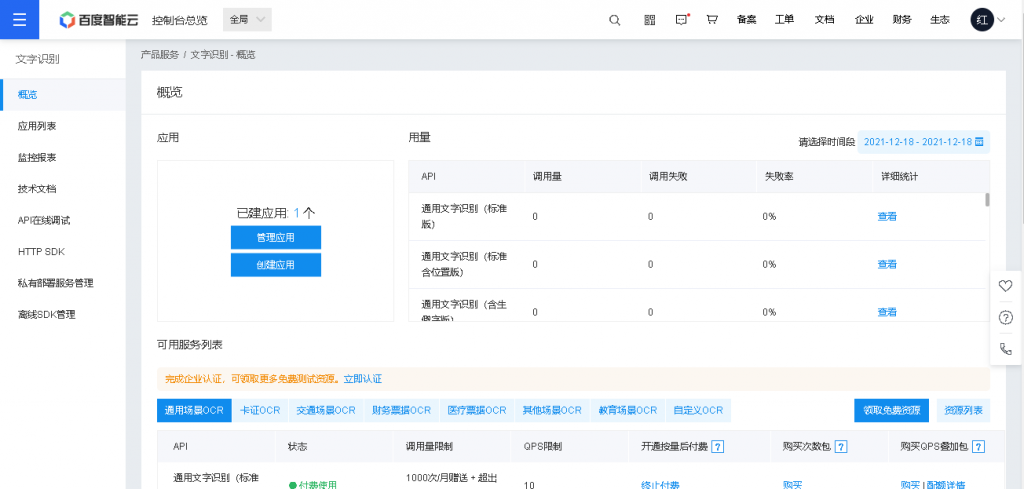
选择“个人”
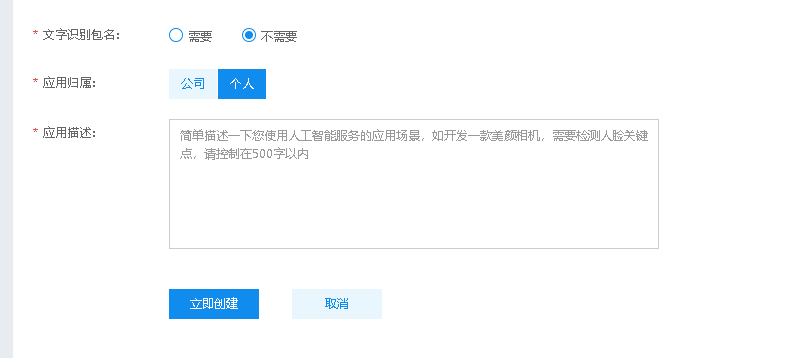
点击“立即创建”,应用就创建好了。
在[应用列表]处会有应用列表,在对应应用处有API Key和Secret Key,请保存好秘钥。
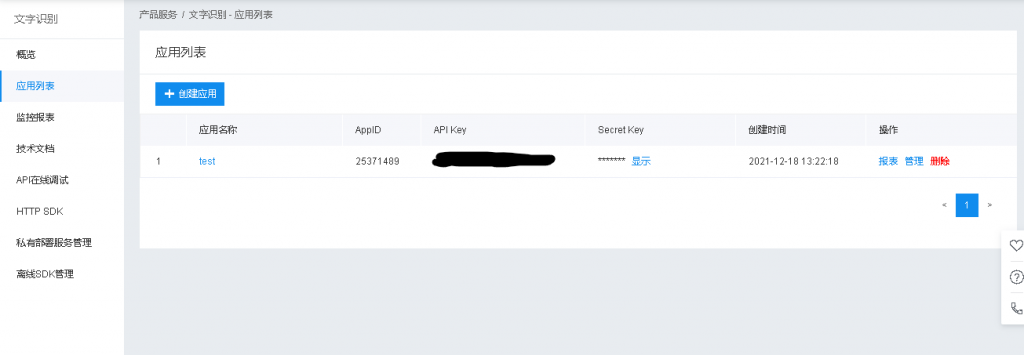
3.2 创建python项目
虽然python可以直接用记事本写,但是一个好的IDE真的会使人心情愉悦,不必为等号两边的空格而烦恼。
这里我使用的是pycharm。
新建一个项目,创建main.py欢迎脚本,在项目根目录新建目录“img”
放入图片到新建的img文件夹内
3.3 贴入代码,运行调试
复制下列代码替换掉main.py中已有的代码
请注意替换代码中的API_KEY 以及 SECRET_KEY,获取位置就是上文提到的应用列表处,并将图片的名称和目录改为你测试用的图片及目录
# coding=utf-8
import sys
import json
import base64
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'GmhC18eVP1Fo1ECX911dtOzw'
SECRET_KEY = 'PQ2ukO4Aec2PTsgQU9UkiEKYciavlZk8'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
调用远程服务
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接通用文字识别高精度url
image_url = OCR_URL + "?access_token=" + token
text = ""
# 读取测试图片
file_content = read_file('img/test.jpg')
# 调用文字识别服务
result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json = json.loads(result)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)在命令行中运行python main.py
运行后控制台会有下列输出:
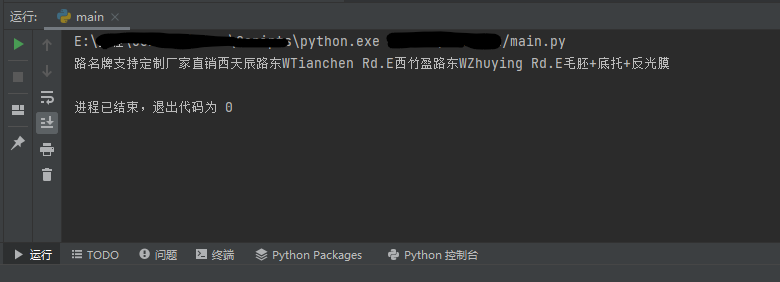
我识别的是网上随便找的一个路牌的广告(